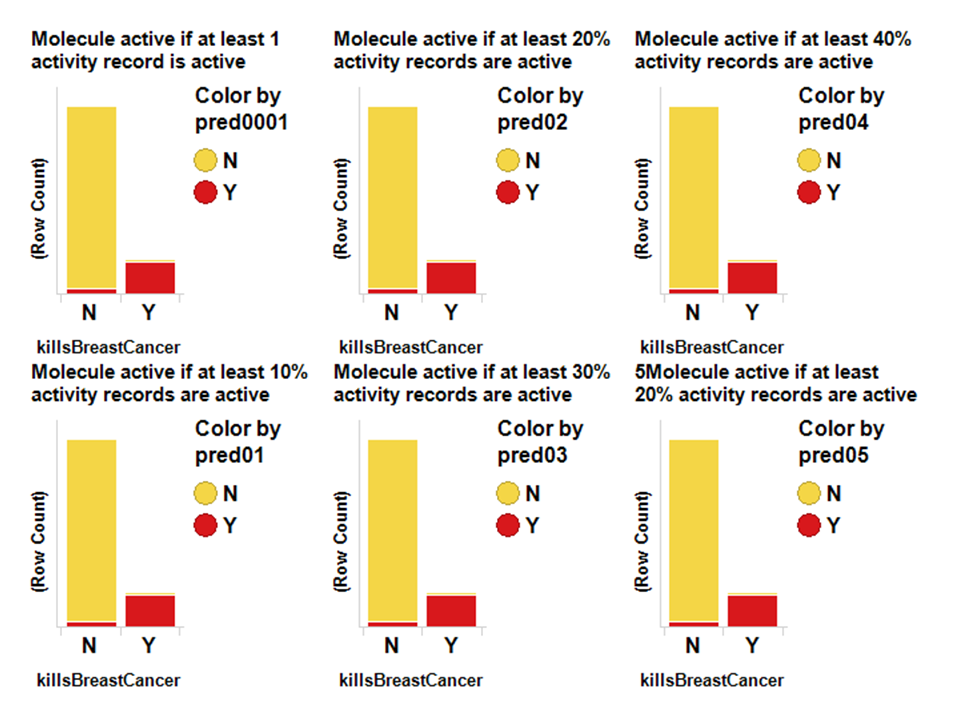
Decision Trees, confusion matrixes.
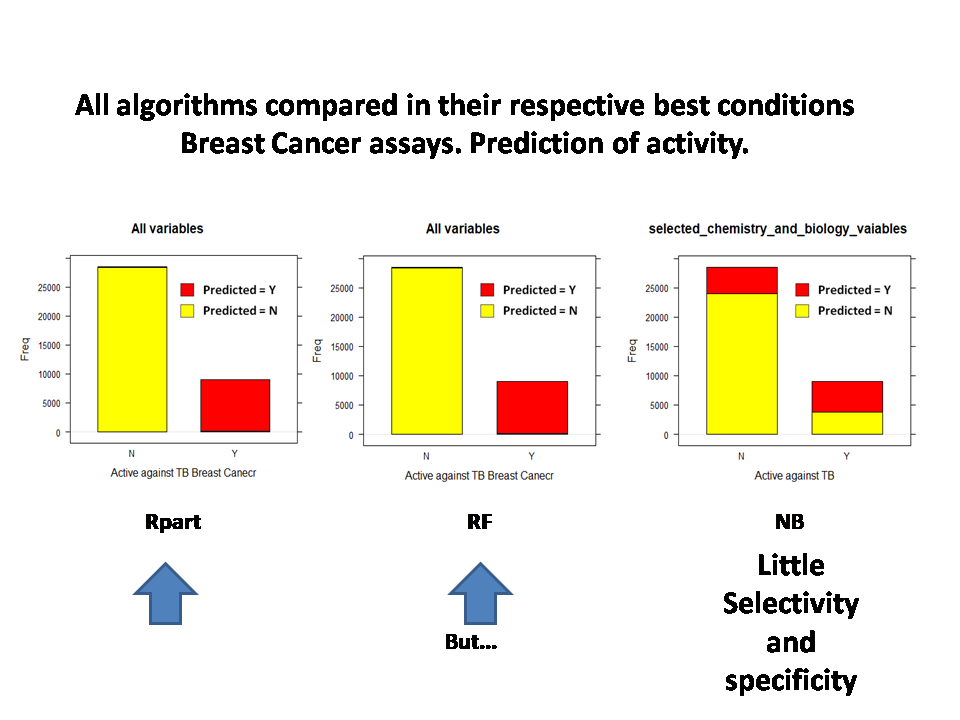
Each individual chart represents the confusion matrix where the beyond the indicated percentage of active instances for each molecule this is predicted as active against Breast Cancer.
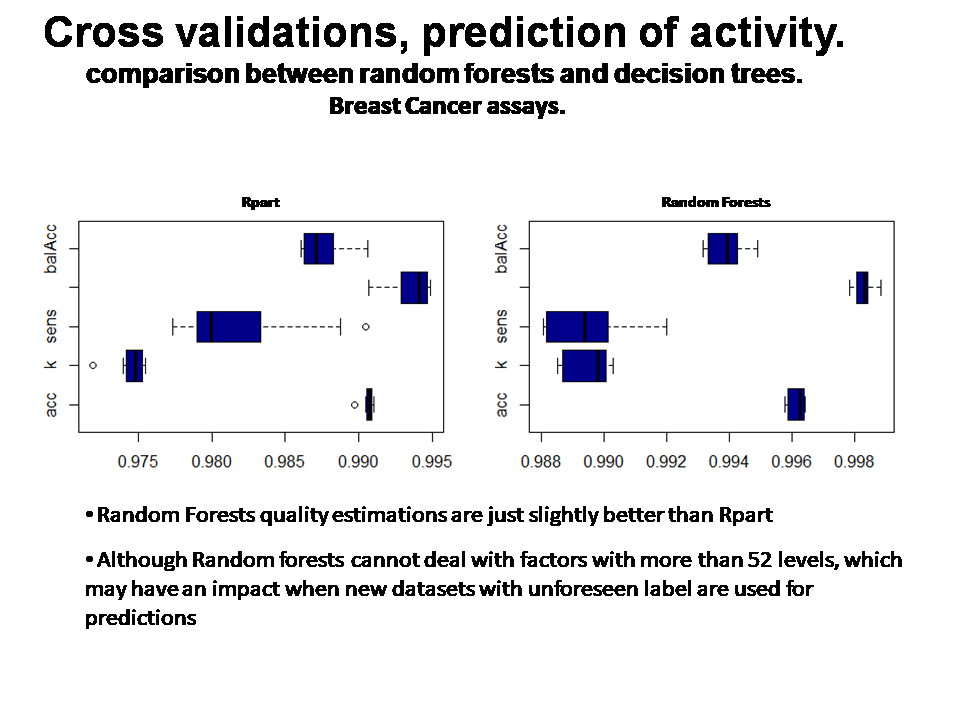
Decision Trees, evaluation of performance statistics.
Rpart using different datasets with different weights on biology and chemistry
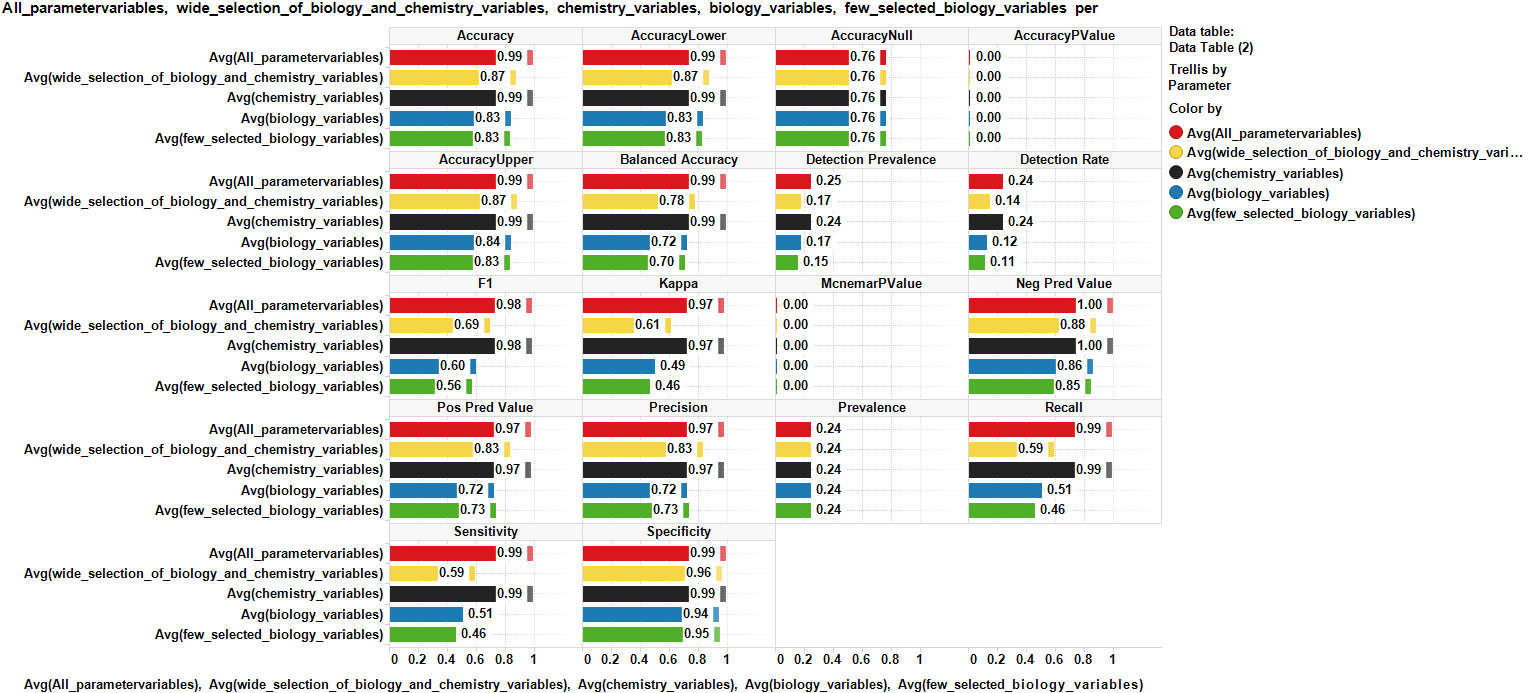
The usage of the whole dataset seems to be advantageous in terms of accuracy, sensitivity, specificity and kappa, although chemistry-associated variables still yield good performance indicators.
Random Forests, evaluation of performance statistics.
randomForest using different datasets with different weights on biology and chemistry
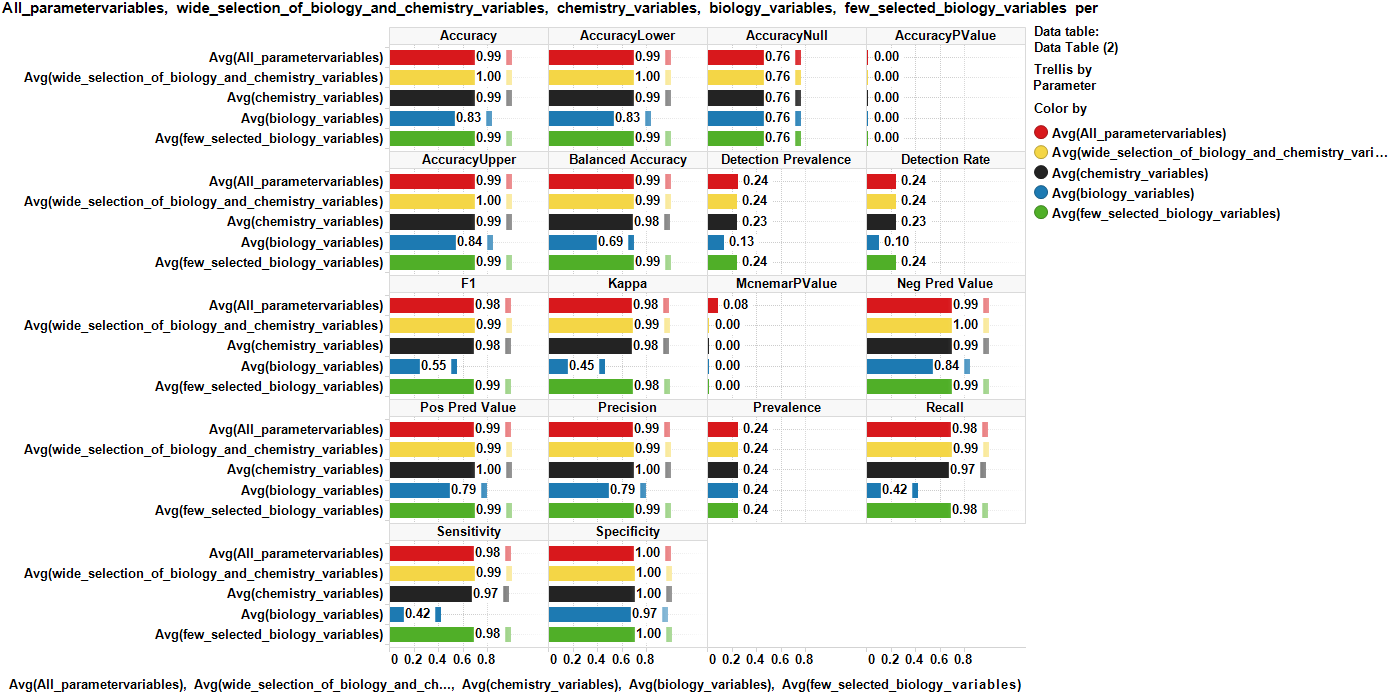
Again, the usage of the whole dataset seems to be advantageous in terms of accuracy, sensitivity, specificity and kappa, although chemistry-associated variables still yield good performance indicators.
Naive Bayes, evaluation of performance statistics.
naiveBayes using different datasets with different weights on biology and chemistry
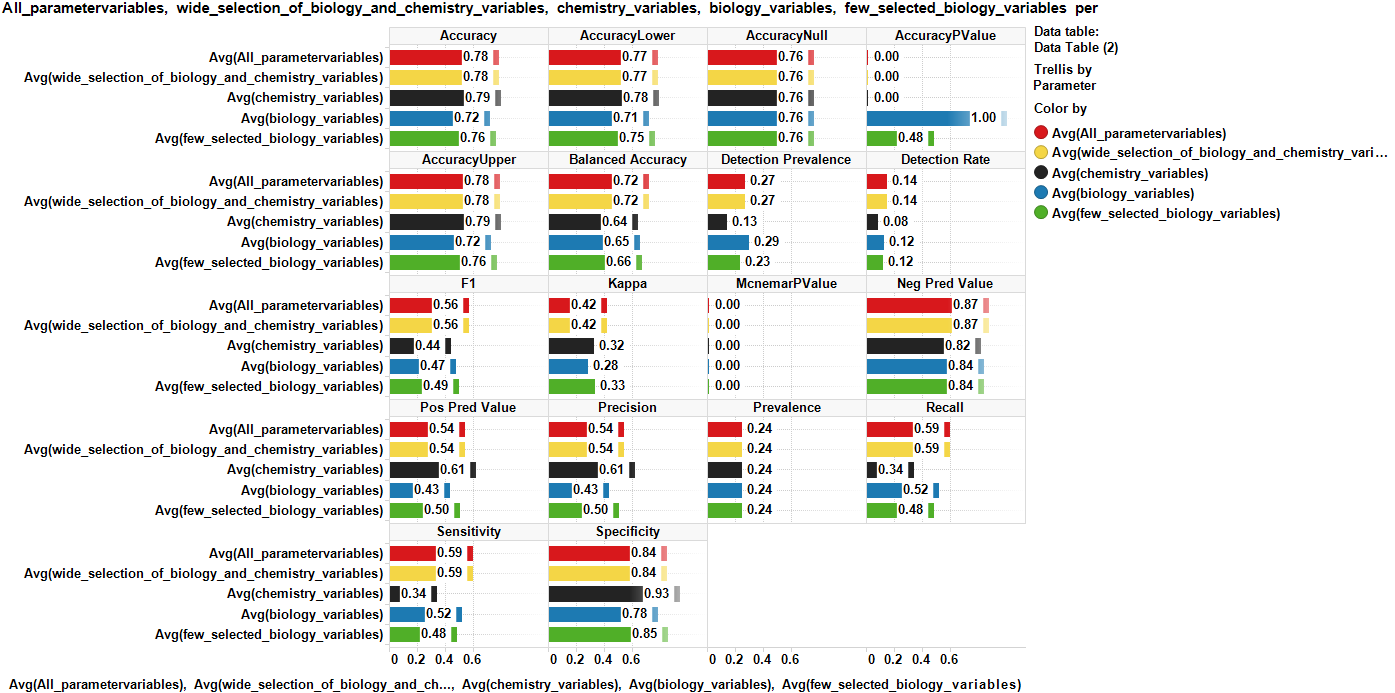 In general, Naive Bayes presents lower quality parameters for Breast Cancer than its Rpart and Random Forest counterparts with little difference wrt the experimental dataset chosen.
In general, Naive Bayes presents lower quality parameters for Breast Cancer than its Rpart and Random Forest counterparts with little difference wrt the experimental dataset chosen.
All algorithms compared for key parameters
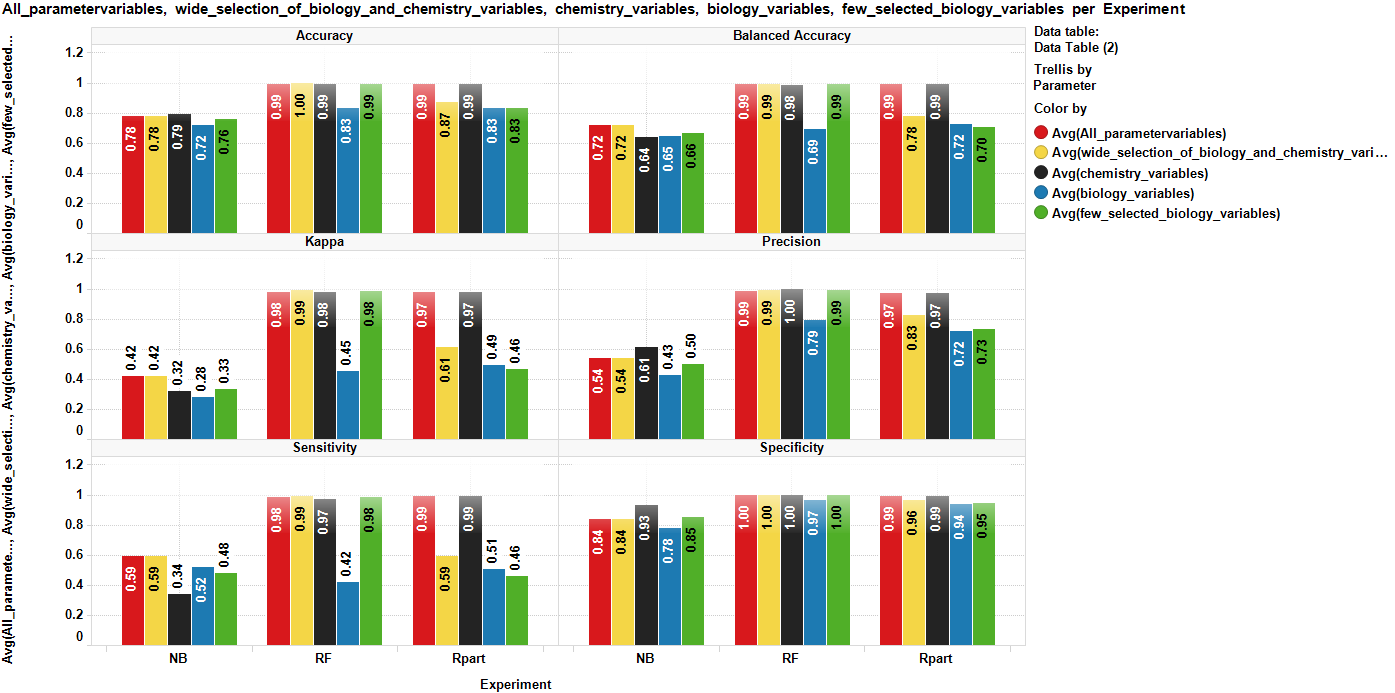
It looks like we want to go with random forests, with the wide set of variables, although decision trees give good statistics as well. Both far better than bayesian algorithms… in this case…
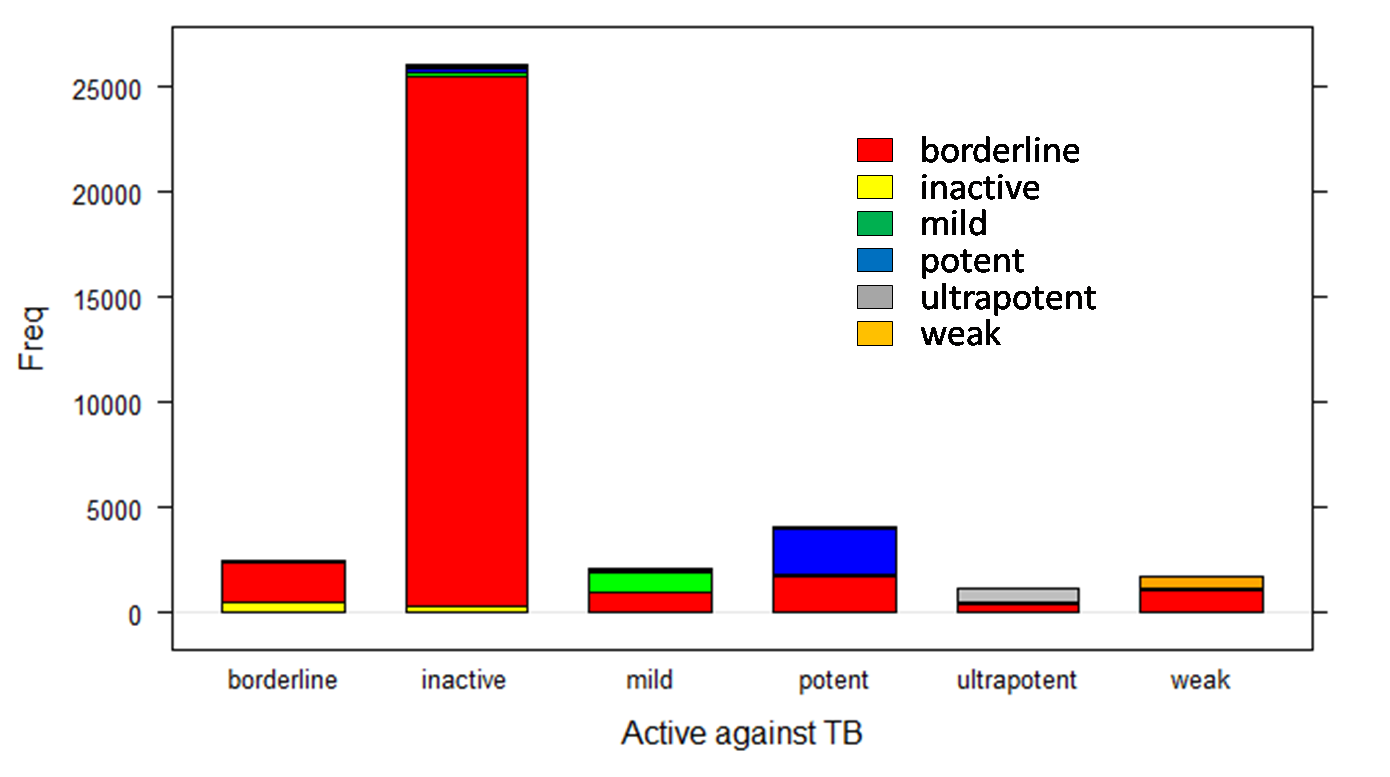
Naive Bayes in multiclass mode
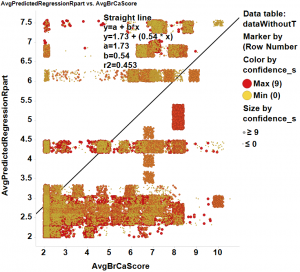
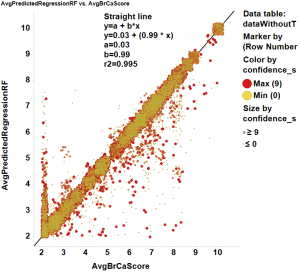
Regressions with forests and trees suggests RF regression as the primary method for prediction.