Machine learning applied to biomedical research.
The use of computational tools in the early stages of drug development has increased in recent decades. Machine learning approaches have been of special interest, since they can be applied in several steps of the drug discovery methodology, such as prediction of target structure, prediction of biological activity of new ligands through model construction, discovery or optimization of hits, construction of models that predict the pharmacokinetic and toxicological (ADMET) profile of compounds, and assessment of mechanism of action and identification of new targets for further research. .
Two public domains, NCBI and ChemBl hold millions of experimental records accessible to the whole biomedical community. The websites support applications to facilitate access to results for limited number of assays or molecules, but they also allow downloads of the database components, sometimes, of the database itself.
This web is an attempt to present an overview on some applications of ML techniques in construction of classification and/or prediction models of biological activity, identification of mechanism of action of molecules active in phenotypic assays and unveiling of potential new targets through pathways analysis.
Predictive analytics deployed in this site
- Prediction of activity of molecules can be useful for the design of small compound collections to make proof of concept on a particular biological. The ad hoc design of compound collections saves costs of research and speeds up the process. Customers may be small biotechs with limited chemistry resources and high focus on novelty, but also big Pharmas that may outsource programs to re-purpose drugs with known activity.
- Target identification has potential interest for biotechs in order to set preferences for their short-mid term portfolios, so as to define pilot studies to assess efficacy and Mechanism of action.
- Pathways analysis is an elegant support to target identification, affording the novelty to the standard TID process.
- Repurposing is the application of known drugsand compoundsto treat new indications (i.e., new diseases). A significant advantage is that since the repositioned drug has already passed a significant number of toxicity and other tests, its safety is known and the risk of failure for reasons of adverse toxicology are reduced. May be of interest for any kind of pharma, even CROs.
- Selection of patients population for clinical trials. Drugs efficacy in humans may change attending to individual profiles. With some previous knowledge from previous studies, a number of patients where efficacy has been predicted optimal can be selected to support an indication on a featured sector of the target population.
- Support pharmacovigilance. Pharmacovigilance is a post-licensing activity of pharmaceutical development consisting on recording adverse effects observed on the prescribed population. Here we can use text analytics upon published sources and social networks coupled to DBs where drug-drug and drug interactions are recorded.
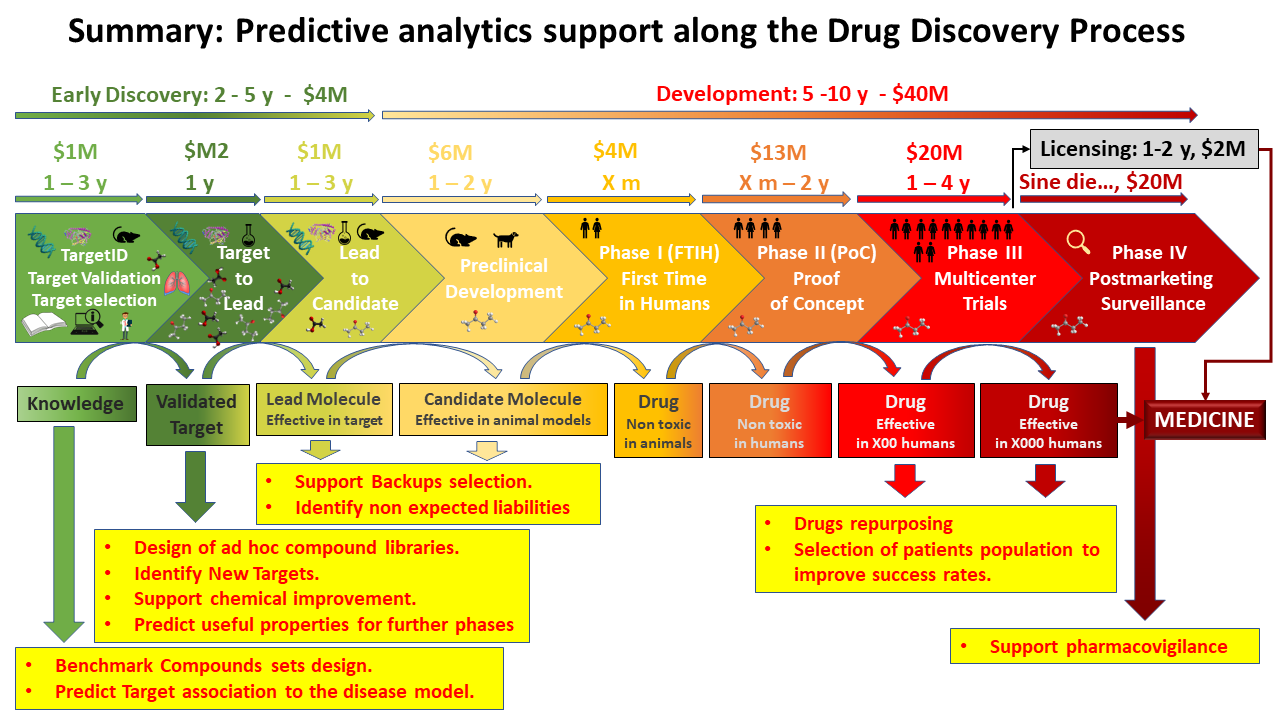
Let’s se now where these activities can fit along the drug disc. overy process
Drug discovery
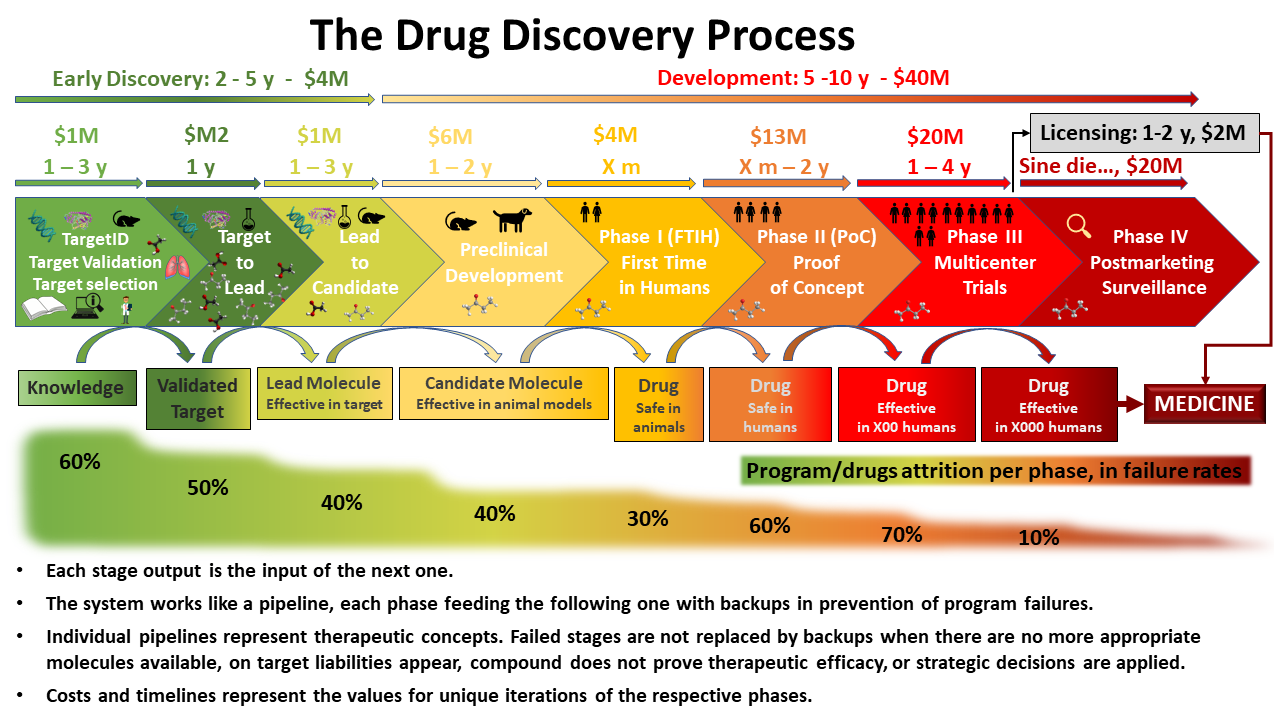
- Early Discovery
- Target identification, validation and selection: A set benchmark compounds is proved active against a documented target and a disease-relevant experimental model based on cells, tissues or animals.
- Target to Lead: Active molecules on an experimental model based on a selected targets are evaluated for potency and selectivity to undergo further optimization based on succeeding iterations from chemical improvement.
- Lead to Candidate: Lead compounds are tested for efficacy, pharmacokinetics, pharmacodynamics and safety.
- Development
- Preclinical Development: Sets safety in animals at increasing doses ahead assays in humans.
- Phase I trials, usually in healthy volunteers, determine safety and dosing.
- Phase II trials are used to get an initial reading of efficacy and further explore safety in small numbers of patients having the disease targeted by the NCE.
- Phase III trials are large, pivotal trials to determine safety and efficacy in sufficiently large numbers of patients with the targeted disease. If safety and efficacy are adequately proved, clinical testing may stop at this step and the NCE advances to the new drug application (NDA) stage.
- Phase IV trials are post-approval trials that are sometimes a condition attached by the FDA, also called post-market surveillance studies.
Target validation
(wikipedia)
The definition of “target” itself is something argued within the pharmaceutical industry. Generally, the “target” is the naturally existing cellular or molecular structure involved in the pathology of interest that the drug-in-development is meant to act on. However, the distinction between a “new” and “established” target can be made without a full understanding of just what a “target” is. This distinction is typically made by pharmaceutical companies engaged in discovery and development of therapeutics. In an estimate from 2011, 435 human genome products were identified as therapeutic drug targets of FDA-approved drugs.[12]
“Established targets” are those for which there is a good scientific understanding, supported by a lengthy publication history, of both how the target functions in normal physiology and how it is involved in human pathology. This does not imply that the mechanism of action of drugs that are thought to act through a particular established target is fully understood. Rather, “established” relates directly to the amount of background information available on a target, in particular functional information. The more such information is available, the less investment is (generally) required to develop a therapeutic directed against the target. The process of gathering such functional information is called “target validation” in pharmaceutical industry parlance. Established targets also include those that the pharmaceutical industry has had experience mounting drug discovery campaigns against in the past; such a history provides information on the chemical feasibility of developing a small molecular therapeutic against the target and can provide licensing opportunities and freedom-to-operate indicators with respect to small-molecule therapeutic candidates.[citation needed]
In general, “new targets” are all those targets that are not “established targets” but which have been or are the subject of drug discovery campaigns. These typically include newly discovered proteins, or proteins whose function has now become clear as a result of basic scientific research.
Predictive analytics support target validation
- By interrogating experimental databases containing results of experimental disease models and identifying unknown targets.
- By defining compound sets with increased probabilities of being active in target validation phase.

Target to Lead
(wikipedia)
The process of finding a new drug against a chosen target for a particular disease usually involves high-throughput screening (HTS), wherein large libraries of chemicals are tested for their ability to modify the target.
It is important to show how selective the compounds identified from screening are for the chosen target, as one wants to find a molecule which will interfere with only the chosen target, but not other, related targets. To this end, other screening runs will be made to see whether the “hits” against the chosen target will interfere with other related targets – this is the process of cross-screening. Cross-screening is important, because the more unrelated targets a compound hits, the more likely that off-target toxicity will occur with that compound once it reaches the clinic.
It is very unlikely that a perfect drug candidate will emerge from these early screening runs. One of the first steps is to screen for compounds that are unlikely to be developed into drugs; for example compounds that are hits in almost every assay, classified by medicinal chemists as “pan-assay interference compounds“, are removed at this stage, if they were not already removed from the chemical library.[13][14][15] It is often observed that several compounds are found to have some degree of activity, and if these compounds share common chemical features, one or more pharmacophores can then be developed. At this point, medicinal chemists will attempt to use structure-activity relationships (SAR) to improve potency, selective and ADME properties of the lead compound. in a process that will require several iterative screening runs.
Predictive analytics support T2L
- Prediction of activity delivers compound libraries with minor sizes and greater probability of on target activity, reducing costs and cycle times.
- Prediction of activity for library design may be performed to enhance selectivity.
- Identification of new targets from the active compounds in the disease-relevant experimental model not active in the target-based experimental scalable model.
- Predictive Analytics can be employed to forecast, among the lead molecules, properties to be examined in later stages, like absorption and elimination rates, potential liabilities, and others, thus supporting Lead selection.

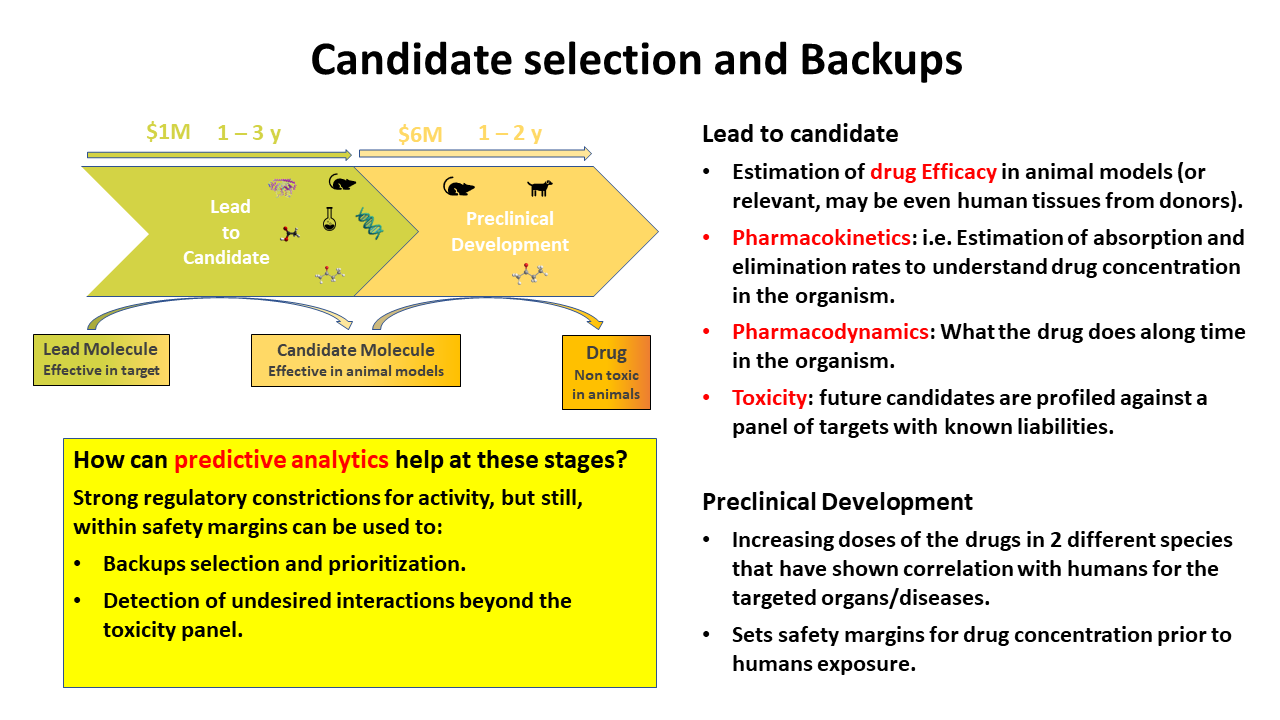
Selection of a Development Candidate
Taken from:

A development candidate is a molecule for which the intent is to begin Phase I evaluation. Prior to submission of an IND, the project team must evaluate the likelihood of successfully completing the IND-enabling work that will be required as part of the regulatory application for first in human testing. Prior to decision point #7, many projects will advance as many as 7-10 molecules. Typically, most pharma and biotech companies will select a single development candidate with one designated backup. Here, we recommend that the anointed “Development Candidate” be the molecule that rates the best on the six criteria below. In many cases, a Pre-IND meeting with the regulatory agency might be considered. A failure to address all of these by any molecule should warrant a “No Go” decision by the project team. The following criteria should be minimally met for a development candidate:
- Acceptable PK (with a validated bioanalytical method)
- Demonstrated in vivo efficacy/activity
- Acceptable safety margin (toxicity in rodents or dogs when appropriate)
- Feasibility of GMP manufacture
- Acceptable drug interaction profile
- Well-developed clinical endpoints
How can predictive analytics help at these stage?
Strong regulatory constrictions for activity, but still, within safety margins can be used to:
- Backups selection and prioritization.
- Detection of undesired interactions beyond the toxicity panel.
Clinical trials
(wikipedia)
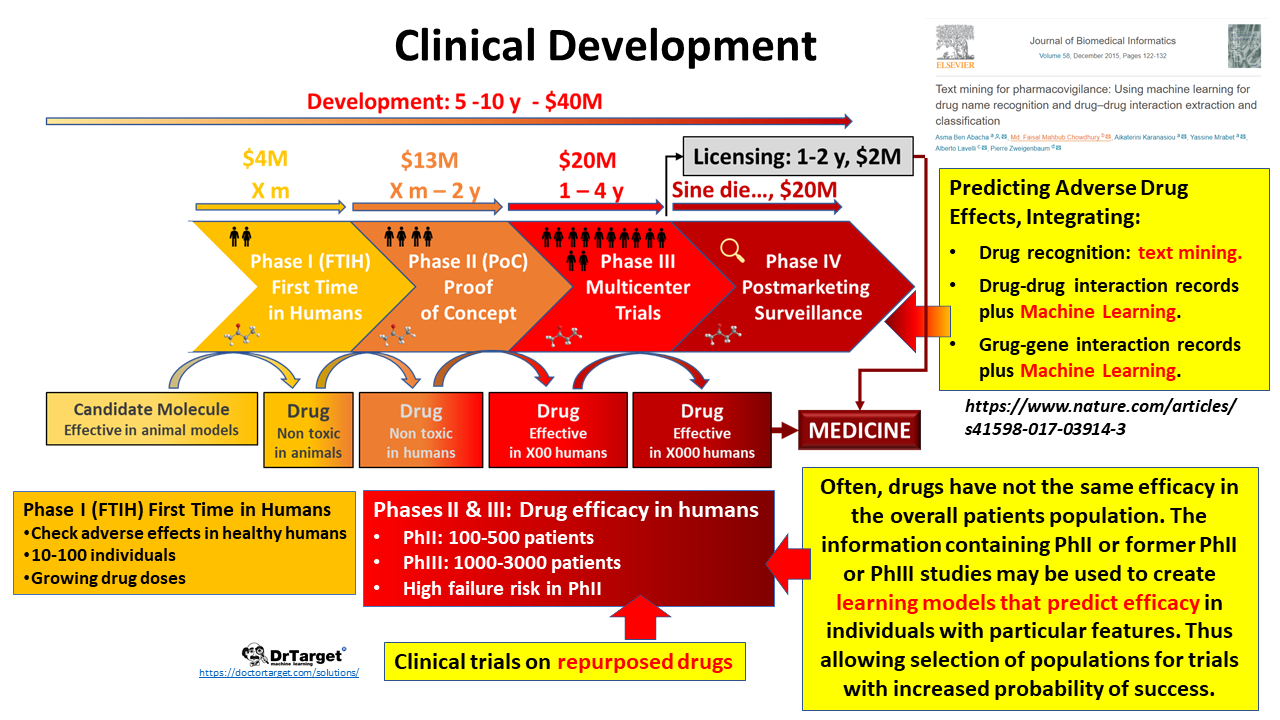
Clinical trials involving new drugs are commonly classified into four phases. Individual trials may encompass more than one phase. A common example of this is combined phase I/II or phase II/III trials. Therefore, it may be easier to think of early phase studies and late phase studies.[1] The drug-development process will normally proceed through all four phases over many years. If the drug successfully passes through Phases I, II, and III, it will usually be approved by the national regulatory authority for use in the general population. Phase IV are ‘post-approval’ studies.
Phase I
Phase I trials were formerly referred to as “first-in-man studies” but the field generally moved to the gender-neutral language phrase “first-in-humans” in the 1990s;[5] these trials are the first stage of testing in human subjects.[6] They are designed to determine the maximum amount of the drug that can be given to a person before adverse effects become intolerable or dangerous. Normally, a small group of 2–100 healthy volunteers will be recruited.[2][6]
Phase II
Once a dose or range of doses is determined, the next goal is to evaluate whether the drug has any biological activity or effect.[1] Phase II trials are performed on larger groups (100–300) and are designed to assess how well the drug works, as well as to continue Phase I safety assessments in a larger group of volunteers and patients.
Phase III
This phase is designed to assess the effectiveness of the new intervention and, thereby, its value in clinical practice.[1] Phase III studies are randomized controlled multicenter trials on large patient groups (300–3,000 or more depending upon the disease/medical condition studied) and are aimed at being the definitive assessment of how effective the drug is, in comparison with current ‘gold standard’ treatment.
Phase IV
A Phase IV trial is also known as postmarketing surveillance trial, or informally as a confirmatory trial. Phase IV trials involve the safety surveillance (pharmacovigilance) and ongoing technical support of a drug after it receives permission to be sold (e.g. after approval under the FDA Accelerated Approval Program).[15]
Predictive analytics supporting these phases;
- Repurposing is the application of known drugsand compoundsto treat new indications (i.e., new diseases). A significant advantage is that since the repositioned drug has already passed a significant number of toxicity and other tests, its safety is known and the risk of failure for reasons of adverse toxicology are reduced. May be of interest for any kind of pharma, even CROs.
- Selection of patients population for clinical trials. Drugs efficacy in humans may change attending to individual profiles. With some previous knowledge from previous studies, a number of patients where efficacy has been predicted optimal can be selected to support an indication on a featured sector of the target population.
- Support pharmacovigilance. Pharmacovigilance is a post-licensing activity of pharmaceutical development consisting on recording adverse effects observed on the prescribed population. Here we can use text analytics upon published sources and social networks coupled to DBs where drug-drug and drug interactions are recorded.
The chart below summarizes the most described applications of predictive sciences along the drug development process.